
Setting Up Velociraptor for Forensic Analysis in a Home Lab
- Sep 20, 2024
- 5 min read

Velociraptor is a powerful tool for incident response and digital forensics, capable of collecting and analyzing data from multiple endpoints. In this guide, I’ll walk you through the setup of Velociraptor in a home lab environment using one main server (which will be my personal laptop) and three client machines: one Windows 10 system, one Windows Server, and an Ubuntu 22.04 version.
Important Note: This setup is intended for forensic analysis in a home lab, not for production environments. If you're deploying Velociraptor in production, you should enable additional security features like SSO and TLS as per the official documentation.
Prerequisites for Setting Up Velociraptor
Before we dive into the installation process, here are a few things to keep in mind:
I’ll be using one laptop as the server (where I will run the GUI and collect data) and another laptop for the three clients.
Different executables are required for Windows and Ubuntu, but you can use the same client.config.yaml file for configuration across these systems.
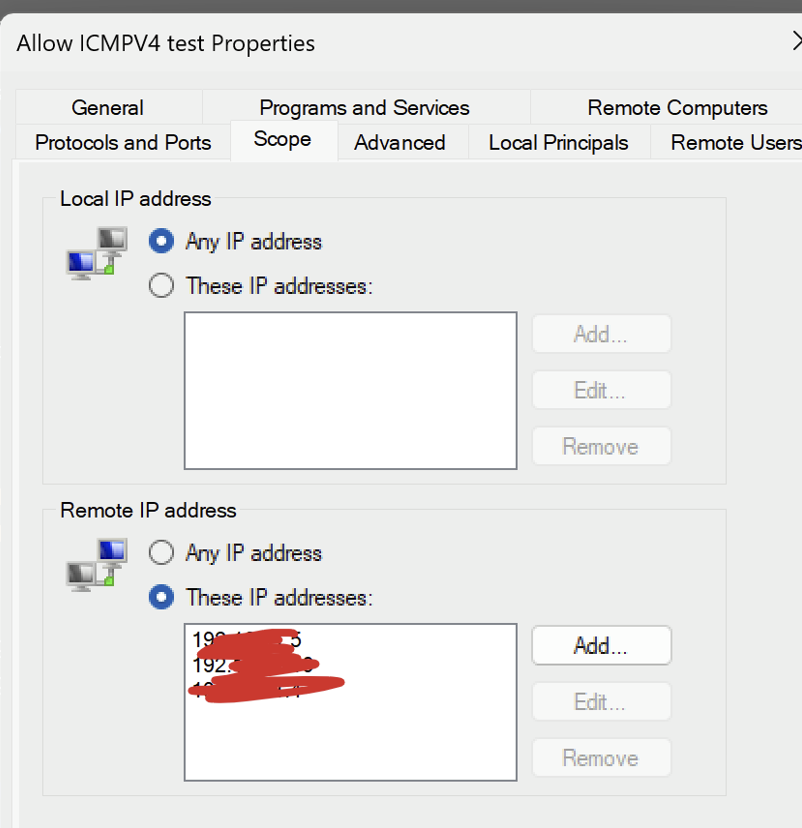
Ensure that your server and client machines can ping each other. If not, you might need to create a rule in Windows Defender to allow ICMP (ping) traffic. In my case, I set up my laptop as the server and made sure all clients could ping me and vice versa.
I highly recommend installing WSL (Windows Subsystem for Linux), as it simplifies several steps in the process, such as signature verification.
If you’re deploying in production, remember to go through the official documentation to enable SSO and TLS.
Now, let's get started with the installation!
Download and Verify Velociraptor
First, download the latest release of Velociraptor from the GitHub Releases page. Make sure you also download the .sig file for signature verification. This step is crucial because it ensures the integrity of the executable and verifies that it’s from the official Velociraptor source.
To verify the signature, follow these steps (in WSL):
gpg --verify velociraptor-v0.72.4-windows-amd64.exe.sig
gpg --search-keys 0572F28B4EF19A043F4CBBE0B22A7FB19CB6CFA1Press 1 to import the signature. It’s important to do this to ensure that the file you’re downloading is legitimate and hasn’t been tampered with.

Step-by-Step Velociraptor Installation
Step 1: Generate Configuration Files
Once you've verified the executable, proceed with generating the configuration files. In the Windows command prompt, execute:
velociraptor-v0.72.4-windows-amd64.exe -h
To generate the configuration files, use:
velociraptor-v0.72.4-windows-amd64.exe config generate -i
This will prompt you to specify several details, including the datastore directory, SSL options, and frontend settings.
Here’s what I used for my server setup:
Datastore directory: E:\Velociraptor
SSL: Self-Signed SSL
Frontend DNS name: localhost
Frontend port: 8000
GUI port: 8889
WebSocket comms: Yes
Registry writeback files: Yes
DynDNS : None
GUI User: admin (enter password)
Path of log directory : E:\Velociraptor\Logs (Make sure log directory is there if not create one)
Velociraptor will then generate two files:
server.config.yaml (for the server)
client.config.yaml (for the clients)Step 2: Configure the Server
After generating the configuration files, you’ll need to start the server. In the command prompt, run:
velociraptor-v0.72.4-windows-amd64.exe --config server.config.yaml guiThis command will open the Velociraptor GUI in your default browser. If it doesn’t open automatically, navigate to https://127.0.0.1:8889/ manually. Enter your admin credentials (username and password) to log in.
Important: Keep the command prompt open while the GUI is running. If you close the command prompt, Velociraptor will stop working, and you’ll need to restart the service.
Step 3: Run Velociraptor as a Service
To avoid manually starting Velociraptor every time, I recommend running it as a service. This way, even if you close the command prompt, Velociraptor will continue running in the background.
To install Velociraptor as a service, use the following command:
velociraptor-v0.72.4-windows-amd64.exe --config server.config.yaml service installYou can then go to the Windows Services app and ensure that the Velociraptor service is set to start automatically.
Step 4: Set Up Client Configuration
Now that the server is running, we’ll configure the clients to connect to the server. Before that you’ll need to modify the client.config.yaml file to include the server’s IP address so the clients can connect

Note: As for me I am running Server in local host. I will not change the IP in configuration file but if you running server on any other do change it.

Setting Up Velociraptor Client on Windows
For Windows, you can use the same Velociraptor executable that you used for the server setup. The key difference is that instead of using the server.config.yaml, you’ll need to use the client.config.yaml file generated during the server configuration process.
Step 1: Running the Velociraptor Client
Use the following command to run Velociraptor as a client on Windows:
velociraptor-v0.72.4-windows-amd64.exe --config client.config.yaml client -vThis will configure Velociraptor to act as a client and start sending forensic data to the server.
Step 2: Running Velociraptor as a Service
If you want to make the client persistent (so that Velociraptor automatically runs on startup), you can install it as a service. The command to do this is:
velociraptor-v0.72.4-windows-amd64.exe --config client.config.yaml service installBy running this, Velociraptor will be set up as a Windows service. Although this step is optional, it can be helpful for persistence in environments where continuous monitoring is required.
Setting Up Velociraptor Client on Ubuntu
For Ubuntu, the process is slightly different since the Velociraptor executable for Linux needs to be downloaded and permissions adjusted before it can be run. Follow these steps for the setup:
Step 1: Download the Linux Version of Velociraptor
Head over to the Velociraptor GitHub releases page and download the appropriate AMD64 version for Linux.
Step 2: Make the Velociraptor Executable
Once downloaded, you need to make sure the file has execution permissions. Check if it does using:
ls -lhaIf it doesn’t, modify the permissions with:
sudo chmod +x velociraptor-v0.72.4-linux-amd64Step 3: Running the Velociraptor Client
Now that the file is executable, run Velociraptor as a client using the command below (with the correct config file):
sudo ./velociraptor-v0.72.4-linux-amd64 --config client.config.yaml client -vCommon Error Fix: Directory Creation
You may encounter an error when running Velociraptor because certain directories needed for the writeback functionality may not exist. Don’t worry—this is an easy fix. The error message will specify which directories are missing.
For example, in my case, the error indicated that writeback permission was missing. I resolved this by creating the required file and directory:
sudo touch /etc/velociraptor.writeback.yaml
sudo chown <your-username>:<your-username> /etc/velociraptor.writeback.yamlAfter creating the necessary directories or files, run the Velociraptor client command again, and it should configure successfully.
Step 4: Running Velociraptor as a Service on Ubuntu
Like in Windows, you can also make Velociraptor persistent on Ubuntu by running it as a service.
Follow these steps:
1. Create a Service File
sudo nano /etc/systemd/system/velociraptor.service2. Add the Following Content
[Unit]
Description=Velociraptor Client Service
After=network.target[Service]
ExecStart=/path/to/velociraptor-v0.72.4-linux-amd64 --config /path/to/your/client.config.yaml client
Restart=always
User=<your-username>[Install]
WantedBy=multi-user.targetMake sure to replace <your-username> and the paths with your actual user and file locations.
3. Reload Systemd
sudo systemctl daemon-reload4. Enable and Start the Service
sudo systemctl enable velociraptor
sudo systemctl start velociraptorStep 5: Verify the Service Status
You can verify that the service is running correctly with the following command:
sudo systemctl status velociraptorConclusion
That's it! You’ve successfully configured Velociraptor clients on both Windows and Ubuntu systems. Whether you decide to run Velociraptor manually or set it up as a service, you now have the flexibility to collect forensic data from your client machines and analyze it through the Velociraptor server.
In the next section, we'll explore the Velociraptor GUI interface, diving into how you can manage clients, run hunts, and collect forensic data from the comfort of the web interface.
Akash Patel
留言